Virtual Cell Models Explained: What Biotech Investors Need to Know










If you've sat through a biotech pitch lately, you've almost certainly heard a founder mention their "virtual cell model" or "in silico platform." The claim usually comes with confidence. What it rarely comes with is a clear explanation of what type of model they're actually running, what it can reliably predict, and what it can't.
That gap matters. The type of model shapes the development timeline, the validation cost, and how far regulators are willing to trust it. This post covers the main model families, what each one actually does, where the reliability floor sits, and what it all means when you're reading a term sheet.
Why virtual cell models exist at all
Drug discovery is fundamentally a process of inferring the effects of treatments on patients, and would benefit enormously from computational models that can reliably simulate patient responses, enabling researchers to generate and test large numbers of therapeutic hypotheses safely and economically before initiating costly clinical trials.
The practical problem is cost and attrition. Industry analyses consistently show that pharmaceutical R&D spend runs into the hundreds of billions of dollars globally each year, and that a large majority of drug candidates fail before reaching patients — with commonly cited estimates suggesting approximately 10% of candidates entering Phase I trials ultimately gain regulatory approval, though figures vary depending on the starting point of measurement, therapeutic area, and methodology of the analysis. A large portion of that loss occurs before a single human trial begins. Virtual cell models are the attempt to catch failures earlier, in silico, before they become expensive wet-lab or clinical failures.
Creating such virtual cells has long been a goal of the computational research community. Recent advances in AI, computing power, lab automation, and high-throughput cellular profiling are now providing new opportunities for reaching that goal.
The challenge is that "virtual cell" covers a wide range of very different approaches, each with different assumptions, different failure modes, and different investment profiles.
The four main model families
1. Whole-cell simulations
The most ambitious category. A whole-cell model attempts to represent every known molecular interaction inside a cell, from gene expression and protein folding through to metabolism and division, as a single integrated computational system.
The goal is to simulate what the cell actually does at a mechanistic level, not just predict one output under one condition. If it works, you can test how a genetic modification ripples across every biological process simultaneously, catching off-target effects that narrower models would miss entirely.
The catch: simulating an entire eukaryotic cell from first principles remains a distant goal. The computational and data requirements are immense. Most published whole-cell models apply to bacteria or minimal synthetic organisms, not human cells. For drug development in oncology, immunology, or rare disease, a true whole-cell model of the relevant human cell type doesn't yet exist at clinical-grade fidelity.
Even partial models that focus solely on metabolism, while ignoring gene regulation, signalling, and cell-wall biophysics, have inherent limitations: they model only the enzymes involved in metabolism, overlooking genes with functions outside metabolic reactions, and fail to capture interactions between different biological processes.
Whole-cell simulations carry the highest theoretical fidelity and the longest, most expensive build cycles. For investors, they represent a bet on whether the team can actually close the gap between the current state of the science and what their model claims to do.
2. Constraint-based metabolic models (CBMs)
This is among the most extensively published and applied mechanistic model classes in industrial biotechnology. Rather than simulating every cellular process, a constraint-based model focuses on metabolic pathways: the chemical reactions that convert inputs into energy, growth, and useful outputs.
Genome-scale metabolic models (GEMs) have become central instruments for mechanistic reasoning in systems biology, enabling in silico exploration of cellular phenotypes under genetic and environmental perturbations through steady-state formulations such as flux balance analysis (FBA) and its many derivatives.
Their appeal lies in a disciplined translation of biochemistry into linear constraints — mass balance, reaction reversibility, and capacity limits — that define a feasible flux space whose optima can be interrogated for growth and other cellular phenotypes.
In plain terms: you give the model a starting condition (available nutrients, genetic constraints) and ask what metabolic flows are mathematically possible. It doesn't simulate dynamics in real time. It asks, given these rules, what steady-state is the cell likely to reach?
Genome-scale metabolic modeling is a growing area of computational biology with rich biotechnology applications, including the study of human metabolism for drug development and the design of synthetic microbial communities for health, environmental, and engineering purposes.
Incorporating omics data into genome-scale metabolic models is a key avenue for improved predictive accuracy. That's also where reliability starts to depend heavily on data quality, which we'll cover below.
The limitation is meaningful: these methods assume that the system is at metabolic steady-state, such that the concentrations of all metabolic intermediates and reaction rates are constant. Real biology doesn't hold still. Cells respond dynamically to stress, to drugs, to their microenvironment. A steady-state model won't capture those dynamics reliably.
For investors, constraint-based models are a well-established workhorse in metabolic engineering. They are faster and cheaper to build than whole-cell simulations, and they have a documented track record in metabolic engineering applications. They have also been used in drug target identification, though predictive accuracy in complex human disease contexts remains variable and context-dependent. The questions to ask: what cell type, what conditions, and what omics data quality underpins the model?
3. Agent-based models (ABMs)
Agent-based models take a fundamentally different approach. Instead of writing equations that describe population averages, an ABM treats each cell (or each cellular component) as an autonomous agent operating under its own rules. Behaviour at the population level isn't pre-programmed. It emerges from the interactions between individual agents.
Equation-based models have been widely used in computational biology, but rules-based agent-based models offer an intuitive framework that encourages computational and experimental collaboration. Multi-scale ABMs can interrogate emergent behaviour of heterogeneous cell agents within dynamic microenvironments and demonstrate how complexity of intracellular metabolism and signalling modules impacts emergent dynamics.
This makes ABMs particularly useful in oncology, immunology, and tissue engineering, where the interesting biology is often at the boundary between individual cell behaviour and population-level outcomes. Tumour heterogeneity, immune cell infiltration patterns, and drug resistance emerging from a small subclone are the kinds of phenomena ABMs are built to capture.
In ABMs, biologically relevant behaviours such as the spatial distribution of cell states are not specified in the model but emerge directly from agent and environment interactions.
The trade-off: agent-based models are computationally expensive to run at scale, and they can be difficult to validate rigorously. Emergent behaviour that looks plausible can still be wrong if the rules governing individual agents aren't well-grounded in experimental data. Differences in emergent behaviour appear between colony and tissue contexts, and there are variable impacts of cell and population heterogeneity on emergent outcomes, which means extrapolating results from a simplified in silico setting to a patient population requires careful benchmarking.
For investors, the question is whether the team has the experimental data to calibrate the agents faithfully, and whether they have a clear path to regulatory acceptance of emergent simulation as evidence.
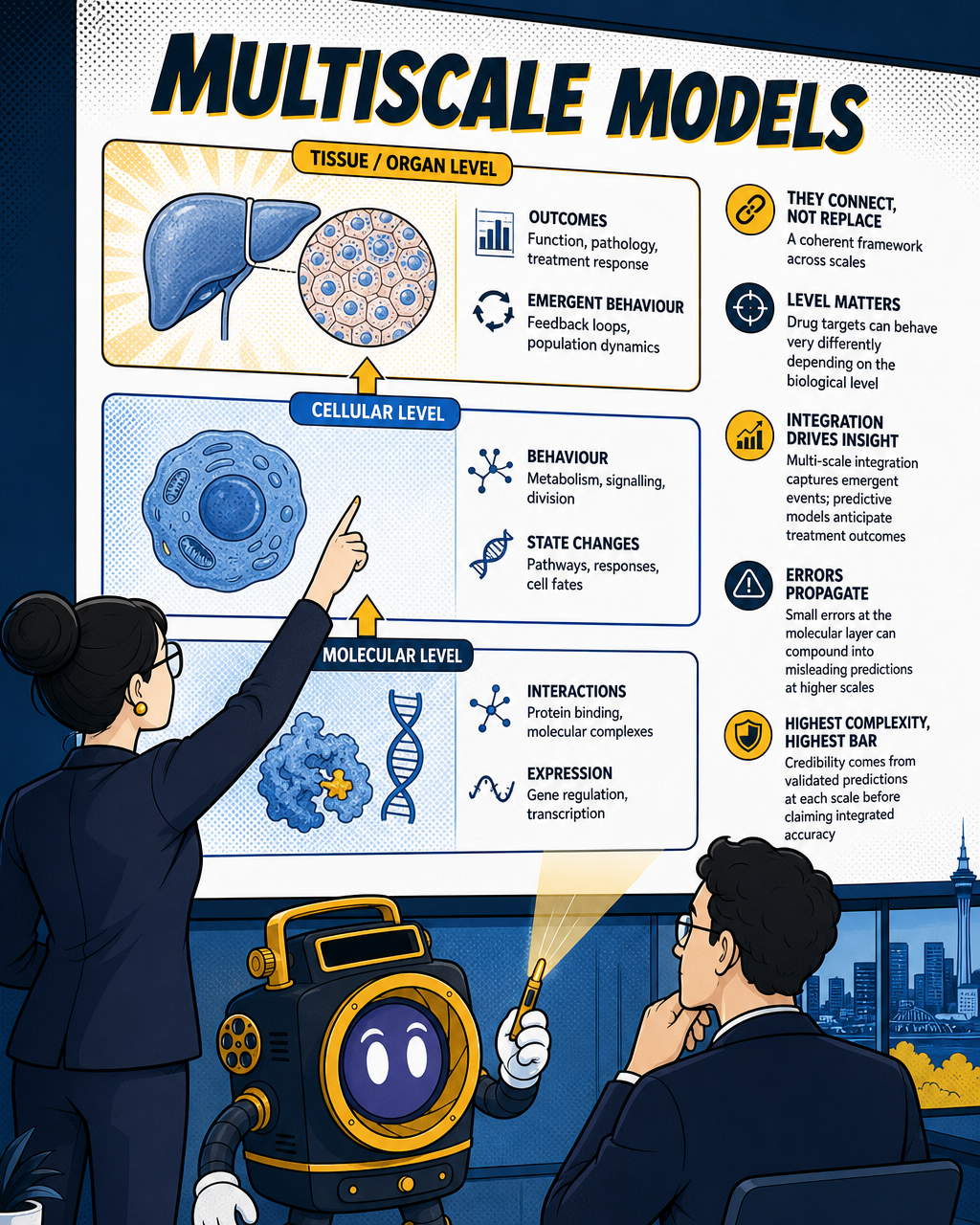
4. Multiscale models
Multiscale models don't replace the categories above. They connect them. The idea is to build a coherent framework that spans molecular interactions at the bottom (protein binding, gene expression) through cellular behaviour in the middle (metabolism, signalling, division) up to tissue or organ-level outcomes at the top.
Multiscale modelling integrates data from molecular, cellular, and tissue levels to elucidate the complexities of disease. This matters most when a drug target behaves very differently depending on the biological level you're looking at. A compound that blocks a receptor cleanly in a molecular simulation can still fail at the tissue level because of feedback loops or cell population dynamics that only emerge at higher scales.
Multi-scale integration ensures coherent connections among molecular, organelle, and cellular data to capture emergent events, while predictive modelling employs computational, statistical, and increasingly AI-driven methods to anticipate the outcomes of genetic modifications or medical treatments.
The build complexity is significant. Significant challenges in multiscale modelling include parameter estimation, model robustness, and the potential for error propagation throughout workflows. An error introduced at the molecular layer can compound as it propagates upward, producing confident-looking tissue-level predictions that are built on shaky foundations.
For investors, multiscale models represent the highest-complexity category. They're most credible when the team can show validated predictions at each individual scale before claiming integrated accuracy across all of them.
The omics data problem
Every model type above is only as good as the data it's built on. This is the part of biotech pitches that often gets glossed over.
Early systems biology sought to reconstruct cellular behaviour through mechanistic or statistical modelling, but these approaches were limited by incomplete knowledge and data sparsity. The situation has improved substantially. With the explosion of omics data and the rise of large language models, researchers can now train foundation models directly on large-scale biological corpora, ranging from nucleotide sequences and single-cell transcriptomes to multi-omic and spatial data.
But volume isn't the same as quality. Incorporating omics data into genome-scale metabolic models is an important avenue for improved predictive accuracy, but only when that data is consistent, well-characterised, and contextually appropriate for the cell type and condition being modelled. Generic transcriptomic data from a cell line that doesn't match the patient population, or proteomic data collected under different conditions from the model's assumptions, will produce unreliable outputs regardless of how sophisticated the model architecture is.
Deep learning models demonstrate powerful data fitting and generation capabilities in virtual cell simulations, but most are "black-box" models that lack explicit expression and constraints of known biological laws. That's a meaningful disclosure risk: a model that fits training data beautifully but can't explain its predictions mechanistically is harder to validate and harder to defend in a regulatory submission.
Physics-Informed Neural Networks address this by incorporating known biophysical laws, dynamic equations, or constraints during the model training process to ensure that predicted results are biologically plausible. This hybrid approach, part data-driven, part mechanistic, is where a lot of the more credible work is happening right now.
The bottom line for due diligence: ask where the training data came from, how it was collected, whether it's specific to the relevant cell type and disease context, and what the model's error rate looks like on held-out experimental data.
What this means for your investment thesis
Model type isn't just a technical footnote. It directly shapes the three variables that matter most to a biotech investor: timeline, validation cost, and regulatory complexity.
Development timeline. Constraint-based metabolic models of well-characterised organisms can be built and iterated in months. A whole-cell simulation of a human disease-relevant cell type is a multi-year research programme. Multiscale models sit somewhere in between, depending on how many scales are being integrated and how much experimental validation data already exists. An investor should ask: what does "the model is built" actually mean, and what experimental milestones must follow before it generates commercially relevant predictions?
Validation costs. Retrospective and prospective validation are costly, requiring high upfront investments and initial adoption by multiple champions. Studies are often hard to justify, particularly when they do not replace existing experiments. This is especially true for ABMs and multiscale models, where emergent predictions are inherently harder to validate against single-experiment benchmarks. It is worth noting that while validation is a significant cost, it is also the primary driver of model credibility, commercial value, and regulatory acceptance — making it a capital allocation decision rather than purely a burden. Iterative validation, entailing the systematic comparison of computational predictions with experimental data, is essential to enhance model accuracy and biological relevance. That process takes time, laboratory resource, and money.
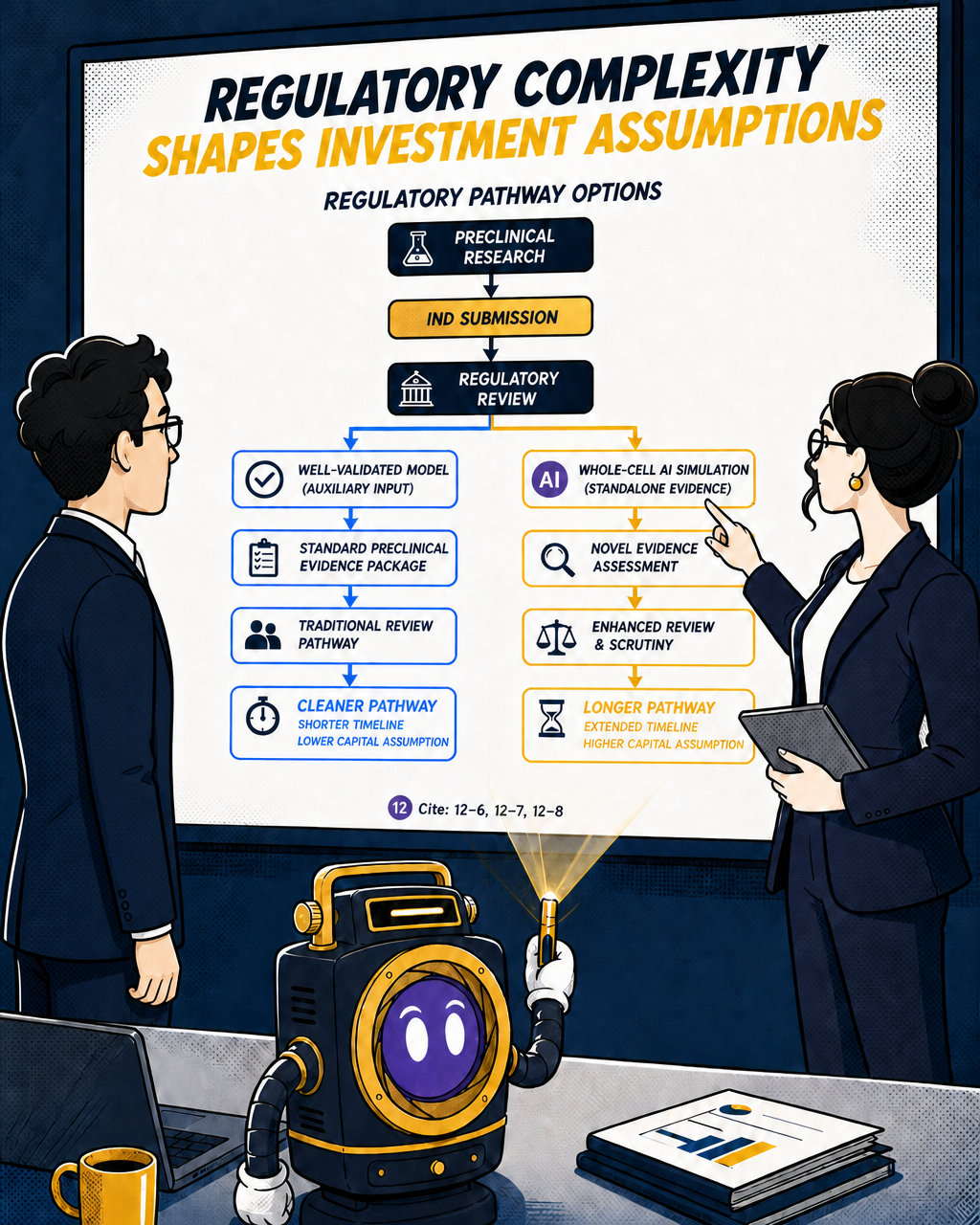
Regulatory complexity. Regulatory agencies including the FDA have issued frameworks encouraging the use of computational approaches in drug development — notably through the Model-Informed Drug Development (MIDD) programme and, in the US, the FDA Modernization Act 2.0 (enacted 2022), which reduced mandatory animal testing requirements and opened pathways for alternative methods including computational modelling. The direction of travel is broadly supportive, though the specifics of what constitutes acceptable evidence vary significantly by context and submission type. As of mid-2026, there remain few precedents for drug approvals relying primarily on AI model outputs, and AI is still predominantly used as an auxiliary tool in regulatory submissions, though the framework continues to evolve.
When submitting regulatory reviews, applicants need to provide sufficient information to demonstrate model reliability while safeguarding patient privacy. Solutions such as federated learning enable multi-institution validation, but these technologies also add complexity and uncertainty to the review process.
The practical implication: a company using a well-validated constraint-based model as one input into a traditional drug discovery programme faces a much cleaner regulatory pathway than one claiming that a whole-cell AI simulation constitutes standalone preclinical evidence. Both can be legitimate investment theses. They carry very different timeline and capital assumptions.
A simple framework for reading the pitch
When a biotech founder tells you their platform runs virtual cell models, four questions will get you most of the way to a useful assessment:
- What type of model is it, specifically? Whole-cell, constraint-based, agent-based, or multiscale? Each carries different maturity and validation requirements.
- What omics data is the model trained or constrained on? Where was it collected, how was it processed, and how well does it match the target disease and cell type?
- What has the model predicted that subsequently matched experimental results? Validation against held-out data, not just training data, is the only meaningful signal.
- How does the model fit into the regulatory strategy? Is it a discovery accelerator, a biomarker qualifier, or is the team claiming it replaces a category of traditional preclinical evidence?
The answers won't always be satisfying. That's fine. The absence of a clear answer to question three is usually the most important thing you learn.
The following section is a paid promotion and does not form part of the editorial content above.
In our experience, one underappreciated contributor to failed biotech pitches is the difficulty of making complex science land clearly for a non-specialist audience. If that sounds familiar, Infrairis builds 60-second explainer videos for exactly this problem, specifically for deep tech and biotech companies in ANZ who need their story to land clearly before the raise window closes.
Related reading
Infrairis
Your complex product. In 60 seconds. Clearly.
Your complex product. In 60 seconds. Clearly.
Learn more about Infrairis and get started today.
Visit Infrairis




